Research
This page describes recent research projects, and contains links to the relevant papers. You might also be interested in my page on Google Scholar or in my résumé.
Policy selection in offline RL
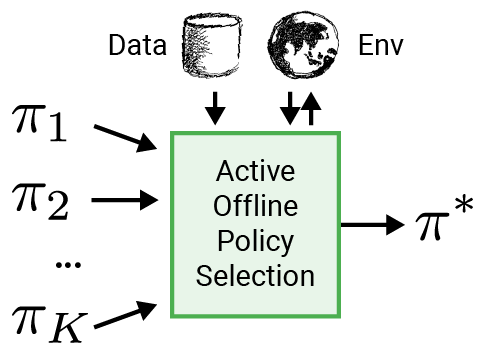
Active offline policy selection
We address the problem of policy selection in domains with abundant logged data, but with a restricted interaction budget. Solving this problem would enable safe evaluation and deployment of offline reinforcement learning policies in industry, robotics, and recommendation domains among others. Several off-policy evaluation (OPE) techniques have been proposed to assess the value of policies using only logged data. However, there is still a big gap between the evaluation by OPE and the full online evaluation in the real environment. Yet, large amounts of online interactions are often not possible in practice. To overcome this problem, we introduce active offline policy selection --- a novel sequential decision approach that combines logged data with online interaction to identify the best policy. This approach uses OPE estimates to warm start the online evaluation. Then, in order to utilize the limited environment interactions wisely we decide which policy to evaluate next based on a Bayesian optimization method with a kernel function that represents policy similarity. We use multiple benchmarks with a large number of candidate policies to show that the proposed approach improves upon state-of-the-art OPE estimates and pure online policy evaluation.
Reward learning and offline reinforcement learning
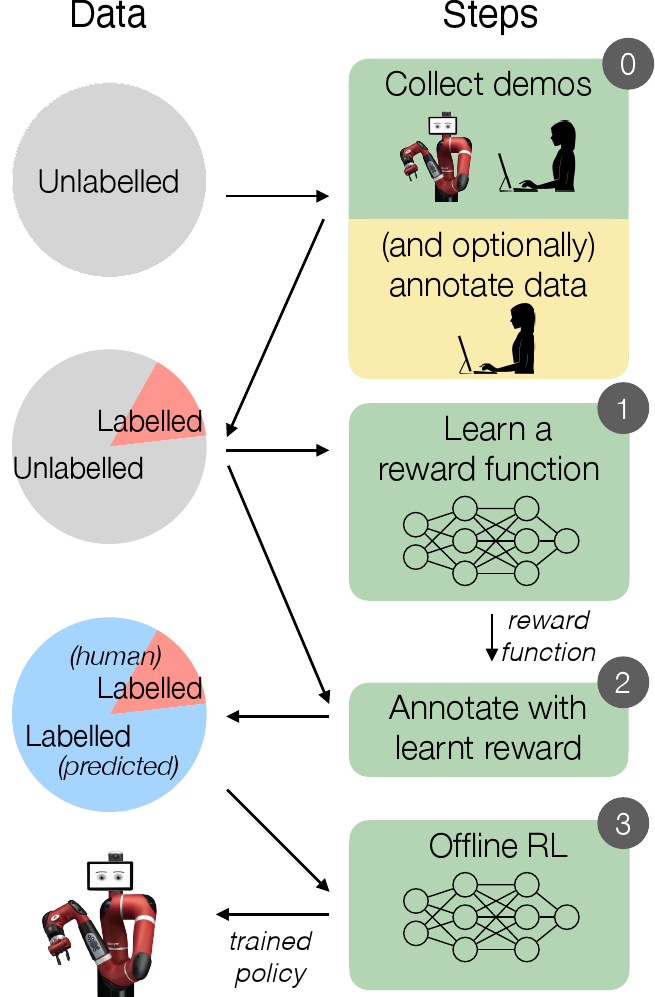
In offline reinforcement learning (RL) agents are trained using a logged dataset. It appears to be the most natural route to attack real-life applications because in domains such as healthcare and robotics interactions with the environment are either expensive or unethical. Training agents usually requires reward functions, but unfortunately, rewards are seldom available in practice and their engineering is challenging and laborious. To overcome this, we investigate reward learning under the constraint of minimizing human reward annotations. We consider two types of supervision: timestep annotations and demonstrations. We propose semisupervised learning algorithms that learn from limited annotations and incorporate unlabelled data. In our experiments with a simulated robotic arm, we greatly improve upon behavioural cloning and closely approach the performance achieved with ground truth rewards. We further investigate the relationship between the quality of the reward model and the final policies. We notice, for example, that the reward models do not need to be perfect to result in useful policies.
-
Semi-supervised reward learning for offline reinforcement learning.
K. Konyushkova, K. Zolna, Y. Aytar, A. Novikov, S. Reed, S. Cabi, N. de Freitas.
PDF video
Behavior cloning (BC) is often practical for robot learning because it allows a policy to be trained offline without rewards, by supervised learning on expert demonstrations. However, BC does not effectively leverage what we will refer to as unlabeled experience: data of mixed and unknown quality without reward annotations. This unlabeled data can be generated by a variety of sources such as human teleoperation, scripted policies and other agents on the same robot. Towards data-driven offline robot learning that can use this unlabeled experience, we introduce Offline Reinforced Imitation Learning (ORIL). ORIL first learns a reward function by contrasting observations from demonstrator and unlabeled trajectories, then annotates all data with the learned reward, and finally trains an agent via offline reinforcement learning. Across a diverse set of continuous control and simulated robotic manipulation tasks, we show that ORIL consistently outperforms comparable BC agents by effectively leveraging unlabeled experience.
Data-driven robotics
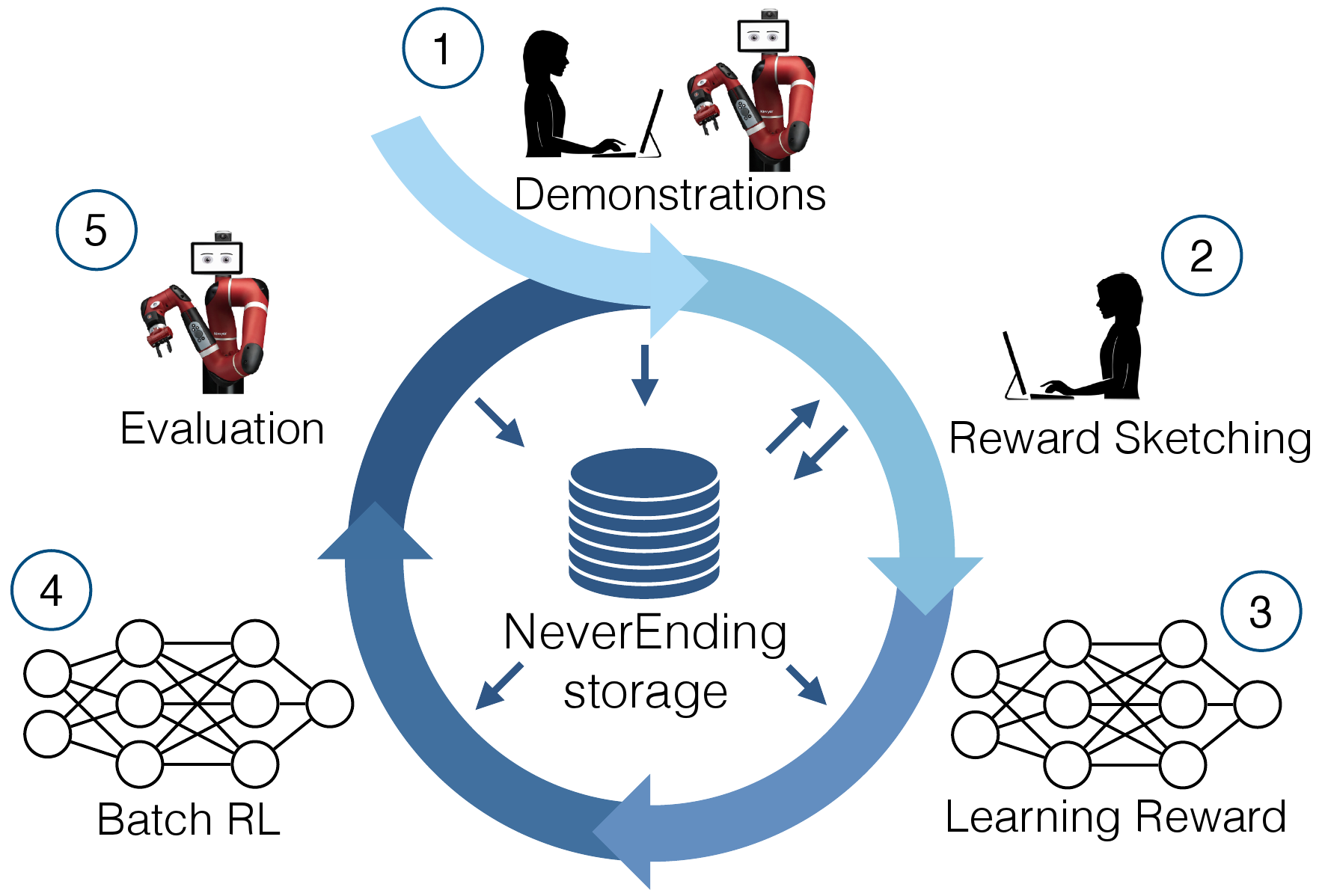
Scaling data-driven robotics with reward sketching and batch reinforcement learning
We present a framework for data-driven robotics that makes use of a large dataset of recorded robot experience and scales to several tasks using learned reward functions. We show how to apply this framework to accomplish three different object manipulation tasks on a real robot platform. Given demonstrations of a task together with task-agnostic recorded experience, we use a special form of human annotation as supervision to learn a reward function, which enables us to deal with real-world tasks where the reward signal cannot be acquired directly. Learned rewards are used in combination with a large dataset of experience from different tasks to learn a robot policy offline using batch RL. We show that using our approach it is possible to train agents to perform a variety of challenging manipulation tasks including stacking rigid objects and handling cloth.
-
Scaling data-driven robotics with reward sketching and batch reinforcement learning.
S. Cabi, S. Gómez Colmenarejo, A. Novikov, K. Konyushkova, S. Reed, R. Jeong, K. Zolna, Y. Aytar, D. Budden, M. Vecerik, O. Sushkov, D. Barker, J. Scholz, M. Denil, N. de Freitas, Z. Wang. RSS 2020.
PDF video website dataset
Learning Active Learning
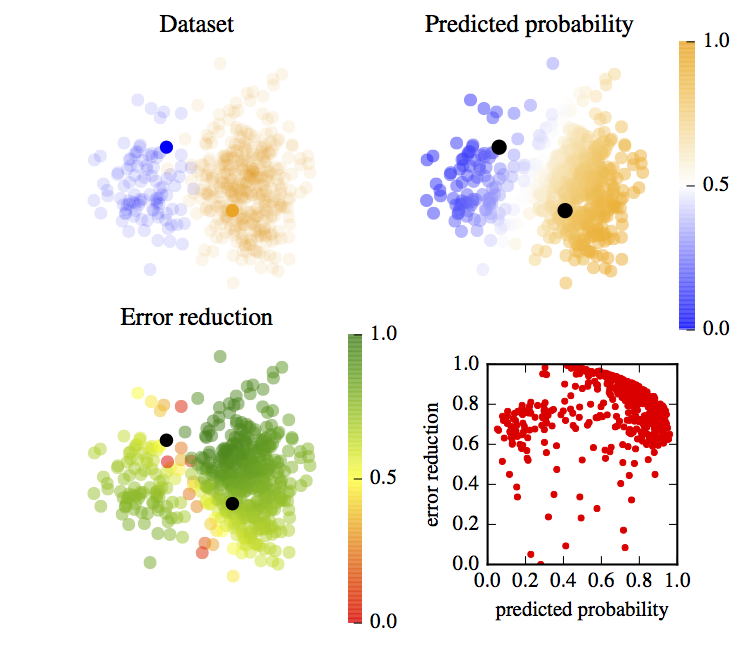
Learning active learning from real and synthetic data
We suggest a novel data-driven approach to active learning (AL). The key idea is to train a regressor that predicts the expected error reduction for a candidate sample in a particular learning state. By formulating the query selection procedure as a regression problem we are not restricted to working with existing AL heuristics; instead, we learn strategies based on experience from previous AL outcomes. We show that a strategy can be learnt either from simple synthetic 2D datasets or from a subset of domain-specific data. Our method yields strategies that work well on real data from a wide range of domains.
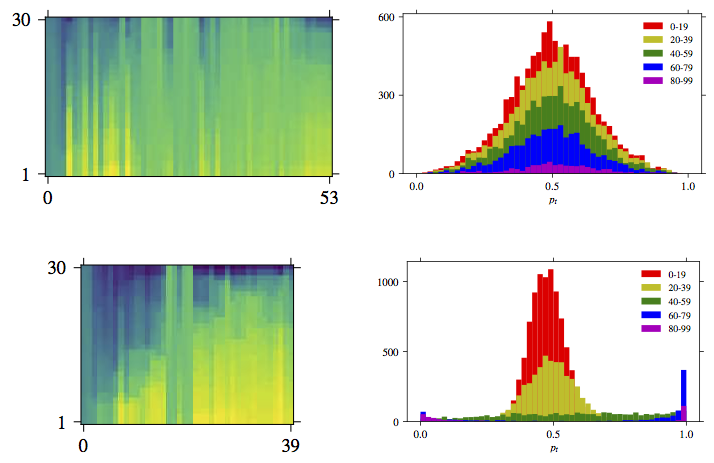
Discovering general-purpose active learning strategies
We propose a general-purpose approach to discovering active learning (AL) strategies from data. These strategies are transferable from one domain to another and can be used in conjunction with many machine learning models. To this end, we formalize the annotation process as a Markov decision process, design universal state and action spaces and introduce a new reward function that precisely model the AL objective of minimizing the annotation cost. We seek to find an optimal (non-myopic) AL strategy using reinforcement learning. We evaluate the learned strategies on multiple unrelated domains and show that they consistently outperform state-of-the-art baselines.
Intelligent Annotation Dialogs
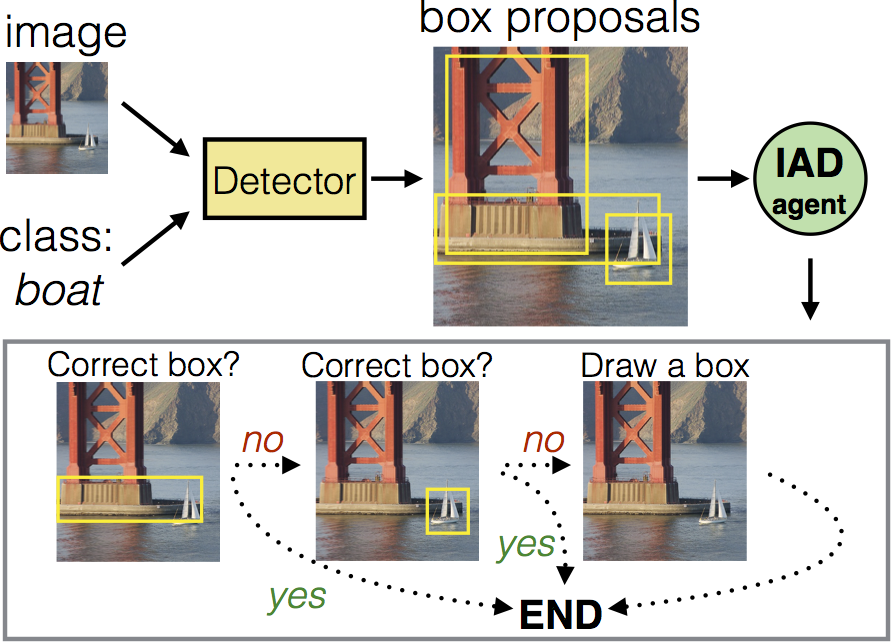
Learning Intelligent Dialogs for Bounding Box Annotation
We introduce Intelligent Annotation Dialogs for bounding box annotation. We train an agent to automatically choose a sequence of actions for a human annotator to produce a bounding box in a minimal amount of time. Specifically, we consider two actions: box verification, where the annotator verifies a box generated by an object detector, and manual box drawing. We explore two kinds of agents, one based on predicting the probability that a box will be positively verified, and the other based on reinforcement learning. We demonstrate that (1) our agents are able to learn efficient annotation strategies in several scenarios, automatically adapting to the difficulty of an input image, the desired quality of the boxes, the strength of the detector, and other factors; (2) in all scenarios the resulting annotation dialogs speed up annotation compared to manual box drawing alone and box verification alone, while also outperforming any fixed combination of verification and drawing in most scenarios; (3) in a realistic scenario where the detector is iteratively re-trained, our agents evolve a series of strategies that reflect the shifting trade-off between verification and drawing as the detector grows stronger.
-
Learning Intelligent Dialogs for Bounding Box Annotation.
K. Konyushkova, J. Uijlings, C. Lampert, V. Ferrari. CVPR 2018.
PDF poster code
Media coverage:
How to learn to segment images without laborious annotation?
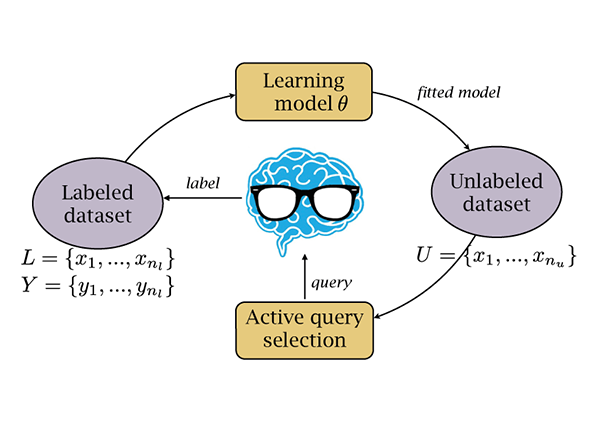
Active learning for image segmentation
We propose an active learning (AL) approach to training a segmentation classifier that exploits geometric priors to streamline the annotation process in 3D image volumes. To this end, we use these priors not only to select voxels most in need of annotation but to guarantee that they lie on 2D planar patch, which makes it much easier to annotate than if they were randomly distributed in the volume. The geometry-inspired AL algorithm is also effective in natural 2D images. Moreover, an extended version of algorithm is developed for the multi-class segmentation problem. We evaluated our approach on binary and multi-class segmentation tasks in Electron Microscopy and Magnetic Resonance image volumes, as well as in natural images. It was demonstrated that the proposed AL approach is capable of dramatically decreasing the amount of tedious labelling for humans. Comparing our approach against several accepted baselines demonstrates a marked performance increase.
God(s) Know(s): analysing children drawings of God(s)
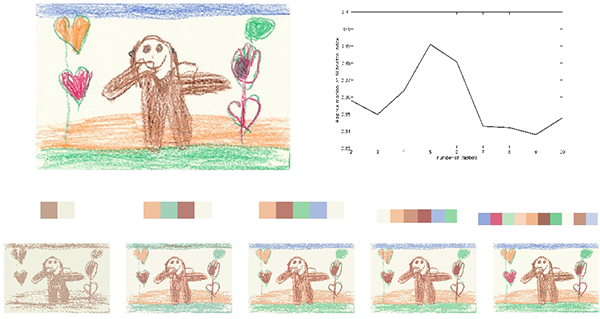
Developmental and cross-cultural patterns in children drawings of God(s)
We analyze the database of God (s) drawings by children from different counties, cultural backgrounds and ages. We detect developmental and cross-cultural patterns in children's drawings of God(s) and other supernatural agents. We develop methods to objectively evaluate our empirical observations of the drawings with respect to: (1) the gravity center, (2) the average intensities of the colors green and yellow, (3) the use of different colours (palette) and (4) the visual complexity of the drawings. We find statistically significant differences across ages and countries in the gravity centers and in the average intensities of colors. These findings support the hypotheses of the experts and raise new questions for further investigation.
-
God(s) Know(s): Developmental and Cross-Cultural Patterns in Children Drawings.
K. Konyushkova, N. Arvanitopoulos, Z. Dandarova Robert, P.-Y. Brandt, S. Süsstrunk.
PDF
Media coverage:
Find me what, don't know what
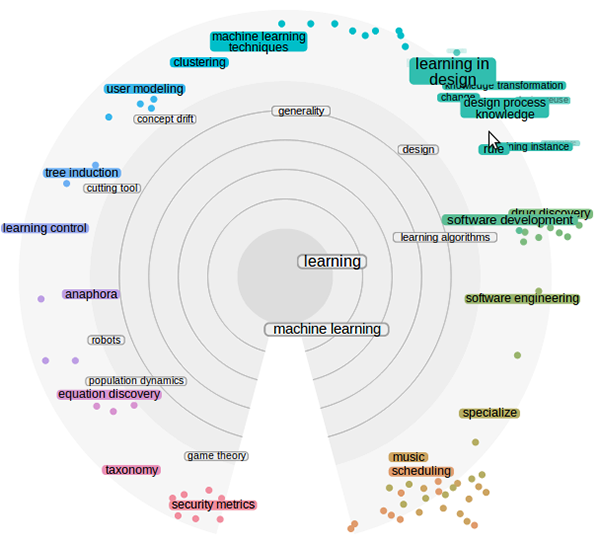
Exploratory search of scientific literature with intent modeling
One of the most challenging tasks of present-day scientists is making sense of the vast amount of scientific literature. In this project I worked in a team of researchers on SciNet, an exploratory information seeking system for scientific literature. SciNet redesigns the query-based search paradigm by combining interactive topical visualization of the information space with a reinforcement learning based user model and search engine. My role in the project was mostly in reinforcement learning user modeling and evaluation of retrieval performance. Through the interactive visualization, the system allows users to navigate in the information space by drilling down to more specific content or explore more general content. The system can assist users even when their goals are uncertain, underspecified, or changing. We evaluated SciNet with twenty scientists, comparing it to the popular query-based alternative Google Scholar. SciNet significantly improved the users' information seeking performance, in particular by offering more novel and diverse results while sustaining the overall quality of the results.
-
Directing exploratory search with interactive intent modeling.
T. Ruotsalo, J. Peltonen, M. Eugster, D. Głowacka, K. Konyushkova, K. Athukorala, I. Kosunen, A. Reijonen, P. Myllymäki, G. Jacucci, S. Kaski. CIKM 2013.
PDF -
Supporting exploratory search tasks with interactive user modeling.
T. Ruotsalo, K. Athukorala, D. Głowacka, K. Konyushkova, A. Oulasvirta, S. Kaipiainen, S. Kaski, G. Jacucci. AISTATS 2013.
PDF -
Scinet: A system for browsing scientific literature through keyword manipulation.
D. Głowacka, T. Ruotsalo, K. Konyushkova, K. Athukorala, S. Kaski, G. Jacucci. IUI 2013.
PDF -
Bayesian Optimization in Interactive Scientific Search
T. Ruotsalo, J. Peltonen, M. Eugster, D. Głowacka, K. Konyushkova, K. Athukorala, I. Kosunen, A. Reijonen, P. Myllymäki, G. Jacucci, S. Kaski. NIPS 2014 workshop on Bayesian Optimization.
PDF
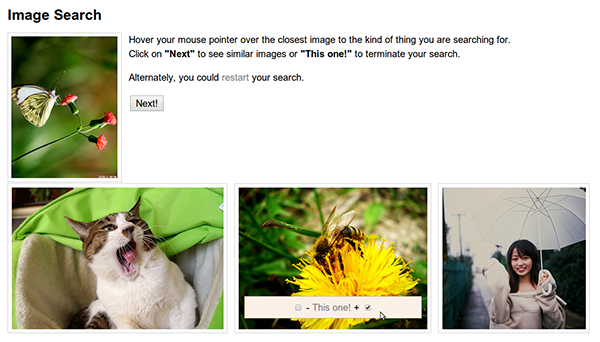
Exploratory image retrieval of vaguely defined targets
We consider a problem of image retrieval in a database of images without matadata such as keywords, tags or natural language text. In the situation when the user is unable to query the system by context, we employ a mechanism for relevance feedback to specify the information needs. For instance, imagine a journalist looking for an illustration to his or her article about loneliness in the database of unannotated photos. The idea of a suitable picture is very vague and the only opportunity for a journalist to navigate is to give relevance feedback to the images proposed by the system. The system operates through a sequence of rounds, when a set of k images is displayed and the user should indicate which one is the closest to their ideal target image.
-
Content-based image retrieval with hierarchical Gaussian Process bandits with self-organizing maps.
K. Konyushkova, D. Głowacka ESANN 2013
PDF -
ImSe: Instant Interactive Image Retrieval System with Exploration/Exploitation trade-off.
K. Konyushkova. M.Sc. thesis, 2013
PDF video slides -
ImSe: Instant Interactive Image Retrieval System with Exploration/Exploitation trade-off.
K. Konyushkova, D. Głowacka
Russian Summer School in Information Retrieval, 2014
PDF